

Group By и Having в SQL
Last updated: 8 мая 2025 г.Далее разберем ключевое слово Group by и having. С помощью Group by можно разбить значения какого-либо выбираемого из таблицы аттрибута на группы.
Группы формируются так, что в каждую из них попадают строки с одинаковыми значениями указанного атрибута. То есть:
- в одной группе — все строки с одним значением,
- в другой — строки с другим значением,
- в третьей — с ещё одним, и так далее.
На примере это будет гораздо понятнее 😉
Для примера добавим в таблицу продукты из прошлых уроков еще пару ламп, еще один вентилятор и еще один стул. Это другие продукты, не те что были раньше, то есть у них будут другая цена, другое количество на складе и т.д. Ниже на картинке добавляем их (поскольку lamp, chair и др. будет повторяться несколько роз, можно представить, что мы добавили другие модели этих продуктов, хотя имя в таблице то же самое).
Добавили.
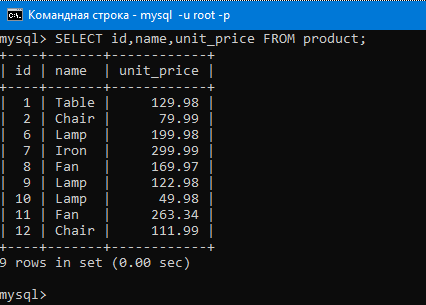
Теперь, что будет если мы совершим группировку по имени (вот так GROUP BY(name)).
Как уже было сказано, GROUP BY засовывает в одну группу одинаковые значения столбца. Групп в итоге будет пять, так как у нас пять разных значений в столбце name.
То есть в первой группе будут три лампы, во второй два вентилятора, в третьей два стула, в четвертой один стол, в пятой один утюг. И самое интересное, что к каждой из этих групп мы можем применить какую-нибудь агрегатную функцию.
Давайте сгруппируем по имени и найдем количество продуктов в каждой группе командой:
SELECT name,COUNT(unit_price) FROM product GROUP BY name;
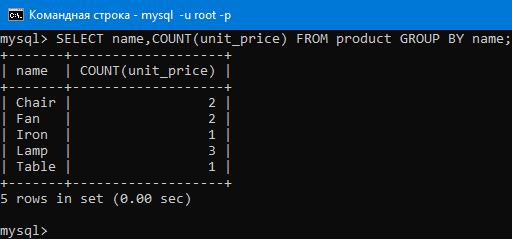
Как видим, результат соответствует тому, что было описано выше.
Запрос происходит в такой последовательности:
Сначала выбираются два столбца — name и unit_price. Потом строки группируются по значению name: все, где name = 'лампа', в одной группе, где name = 'вентилятор' — в другой и т.д. После этого для каждой группы считается, сколько в ней строк — с помощью COUNT(unit_price).
И теперь мы подошли к ключевому слову HAVING, которое используется ТОЛЬКО ЕСЛИ перед ним использовалось GROUP BY.
Представим, что над результатом того что получилось в результате предыдущей команды с GROUP BY нам нужно выполнить ЕЩЕ какие-то действия, то есть отфильтровать результат команды SELECT name,COUNT(unit_price) FROM product GROUP BY name; еще по какому-нибудь дополнительному условию.
Для этого применяется HAVING.
Для примера давайте выведем только те строки предыдущего результата, у которых COUNT(unit_price) больше 1. Это можно сделать запросом SELECT name,COUNT(unit_price) FROM product GROUP BY name HAVING COUNT(unit_price)>1;
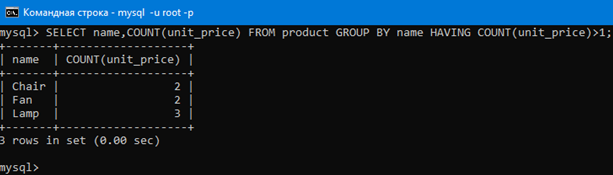
Теперь вывелись только группы, в которых колличество строк больше 1.

Следующие уроки
Подзапросы в SQL
10
мин.

Объединение таблиц в SQL с помощью JOIN
16
мин.
Основы JDBC в Java
15
мин.